We perceive randomness every day whether it’s the shape that clouds take or the number of red lights we face during our commute, so it is not surprising that our intuition is well suited to some of these phenomena. The human mind attempts to bring order to the chaos as it were, and in doing so can discover patterns that can easily escape computers. The flip side of this ability is the ease at which we can convince ourselves that there is a pattern where none exist.
In the picture below, I’ve had the computer plot 100 random points.

Looking at the image, it is not hard to believe that it is a random collection of points; but how do we define random (and I don’t mean a technical definition)? Since negatives make poor definitions[ref]For an example of this consider this definition of a horse: “a car without wheels and which eats grass”.[/ref], we shouldn’t say that this image is random since there is no pattern to the points. We could say that it is random since the points were choose without regard for the existing points, but do points ever ‘know’ about the other points?
Well one of the defining features of randomness, as I perceive it, is that it forms clumps. Not a lot of clumps, but always a couple given enough points. In fact, a set of “random” points without clumps couldn’t actually be random[ref]At least if there are enough points, it would be hard to say if there is or isn’t a clump given 3 points.[/ref].
Consider flipping a coin. While a string of 10 heads may seem unlikely, it is just as probable as flipping H T H T H T H T H T (alternating). Intuitively you may consider a relationship between the length of a sequence and the number of “clumps” within it. For example, a set of 10 coin flips can have anywhere between 1 (all the same) and 5 (e.g. HH TT HH TT HH) clumps in it if we define a clump as any repeating sequence of flips[ref]With this definition we can even say that there are no clumps if we alternate sides with every flip: H T H T H T H T H T[/ref]. Obviously both of these extremes are not representative of our idea of “random”, so let’s take a look at some sample coin flips and count the number of clumps in each (in parenthesis).
- H TT HH TTTT H (3)
- T HHH T H TT H T (2)
- H T HH T H TTT H (2)
- TT H TT H TT HH (4)
- H T H T H TTTTT (1)
- T HHH TT H T H T (2)
For this small sample we can already see playing out some of the patterns our intuition might expect to see. The clumps take on various lengths, and there are more short clumps than long ones (harder to make long clumps). Also it seems easier to make fewer clumps than many clumps, but that again comes from the idea that once you have two clumps, the number of coin flips left it at most 6 and as few as 0 so making more clumps becomes evermore challenging as the number of established clumps increases.
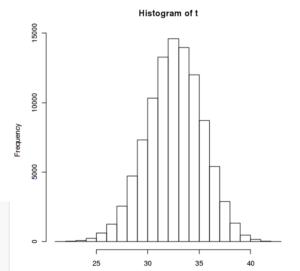 To the right is a histogram of this same procedure on simulated sets of 100 coin flips repeated over 10,000 times. Here $t$ is the number of clumps in a set, so per the plot was can see that on average there were 32-33 clumps in a given set of 100 coin flips. We can also see that the tails of this distribution drop off quite quickly indicating that the odds of having a set of coin flips with fewer than 25 or more than 40 clumps are quite low.
To the right is a histogram of this same procedure on simulated sets of 100 coin flips repeated over 10,000 times. Here $t$ is the number of clumps in a set, so per the plot was can see that on average there were 32-33 clumps in a given set of 100 coin flips. We can also see that the tails of this distribution drop off quite quickly indicating that the odds of having a set of coin flips with fewer than 25 or more than 40 clumps are quite low.
It appears that the expected number of clumps (that is the mean value in a bootstrap analysis such as ours) in a sequence is approximately 1/3rd of the total length of the sequence when dealing with a binary processes (i.e. two state machines such as coin flips: H or T). We would expect that the number of expected clumps would decrease as the number of possible states increase since it is more difficult to create a clump when rolling dice compared to flipping coins.
Running such an analysis for three and size possible states shows that our intuition was correct, the expected number of clumps drops off with the addition of more states. In fact, the expected value $\epsilon$ can be predicted based on the number of states $s$ and the length of the sequence $l$ by this formula:
$$ \epsilon = l\cdot\frac{1}{1+s}$$
Here are the plots of $s=3$ and $s=6$ respectively using the same setup as for the original.


Okay, so this sort of analysis may be helpful in determining how likely a particular sequence may be based on the number of clumps (if it has too many or too few then we may decide that the sequence is not random), but how can we extend this to something like points? Points, unlike our coin flips, live in a continuous domain[ref]Assuming we’re discussing the traditional x,y Cartesian points people are familiar with: $p\in \mathbb{R}^2$.[/ref] how are we to determine the number of ‘states’ available to them?
Well, if we accept $\inf$ as the number of states in a continuous domain, then our formula says that the expected number of clumps is 0. In other words, no two points should coincide, which is actually the right answer. The odds of two random numbers being the same is literally 0, it is impossible.
Although this result does make for a simple test, it is rather restrictive since it can only pick out sets of points that are definitely not random. It cannot, conversely, say if a set is random. In all likelihood we wont find a perfect test (like most things) but it would be helpful to develop a series of tests that can tell us “probably random” or “unlikely to be random”. So let’s see where we get.
The 1-D Case
One of the most powerful ways to visualize the structure within a set of data is to look at its distribution by plotting either a histogram of the data or the empirical probability distribution function (epdf). A histogram uses arbitrarily sized bins to show how the data may or may-not cluster around particular values. The epdf does the same thing but instead of using bins, it assigns a distribution, typically normal, to each data point and then sums them together. I prefer the ecdf since it doesn’t rely of using a fixed number of bins[ref]The ecdf does require a somewhat arbitrary parameter called the bandwidth when it creates the distributions for each point. A low bandwidth results in narrow distributions which yield a jagged epdf plot.[/ref], and reflects the continuous spectrum of values better than the equivalent histogram.
Here are two plots of a ecdf and histogram using different parameters for each.

Starting with the histograms at the bottom, we can see that the number of bins we choose has a large impact of how the distribution looks. The more bins, the more holes there will be between data points, we can also see how fewer bins work to fill in the space at the expense of resolution (e.g. the point in the first block in the histogram to the left could have any value between 0 and 2). Above the histograms are two epdf plots with two different smoothing coefficients, or bandwidths. Notice some of the same trade-offs as with the histogram.
Either of these two approaches allow us to take a set of data, like that listed below, and visually check for clusters. While it would be quite difficult to do so from the numbers themselves, the plots show us that there are likely two clusters, a smaller one on the left and a larger one of the right.
9.70311210725844 11.089099483141 17.4756800551075 14.5499622061104 18.2268516956874 18.2848629759782 13.928134628478 14.6594526326256 11.0008289106312 5.62251325739993 16.2393226847278 18.0814950732004 11.6798374201278 6.5815490491875 15.6013093893462 13.8540959995398 12.3490373612377 16.7131426544832 13.6645814660127 14.2619264851928 2.21321 3.2112 1.2 6.3
Extend to two or more dimensions
To be continued…