Data compression is one of those things that most people don’t really think about. We all know about the benefits of using a ZIP file if our attachment is too large or if we have a bunch of files we want to share with someone over email. Outside of those niche uses, data compression by the end user has largely fell by the wayside in our day of terabyte hard drives and massive USB dongles. And that may be just as well since we’re likely more productive not having to go through the extra step of unpacking an archive before using the files within, yet I’ve always been interested in the subject of data compression.
Data compression, in a non-technical definition, is nothing more than an algorithm(s) which takes the input data and represents it in a more compact form. For example, you could well imagine a text file which contains all record of all of today’s NASDAQ trades:
08/12/2016 9:00am Sold 10 IBM 08/12/2016 9:00am Buy 5 KO 08/12/2016 9:01am Sold 25 GE 08/12/2016 9:02am Buy 10 GOOG ...
Obviously such a file would contain the string “08/12/2016” a whole lot of times, and this is a compression utility’s bread and butter sort of problem. This redundancy is leveraged by replacing the string with a shorter string such as “\a” so now the compressed file would look like:
\a 9:00am Sold 10 IBM \a 9:00am Buy 5 KO \a 9:01am Sold 25 GE \a 9:02am Buy 10 GOOG ...
While it might not look like much, that simple switch replaced 10 characters with 2 and would yield a file size savings of about 26%. Not bad for one simple substitution.
Clearly the techniques and algorithms involved can become quite complicated, but it is useful to know that at its most basic level compression algorithms simply replace one representation of data (the original) with another representation (compressed form).
To take a look at the performance of a sampling of the compression tools out there, I’ve decided to use Matt Mahoney’s 10 GB corpus which contains a variety of every-day files. The corpus was designed to be representative of typical data including images, documents, executables (.exe), and a smattering of some others so as to determine the performance of compression programs on a set of “generic” data. So without any more introduction, here’s what I found.
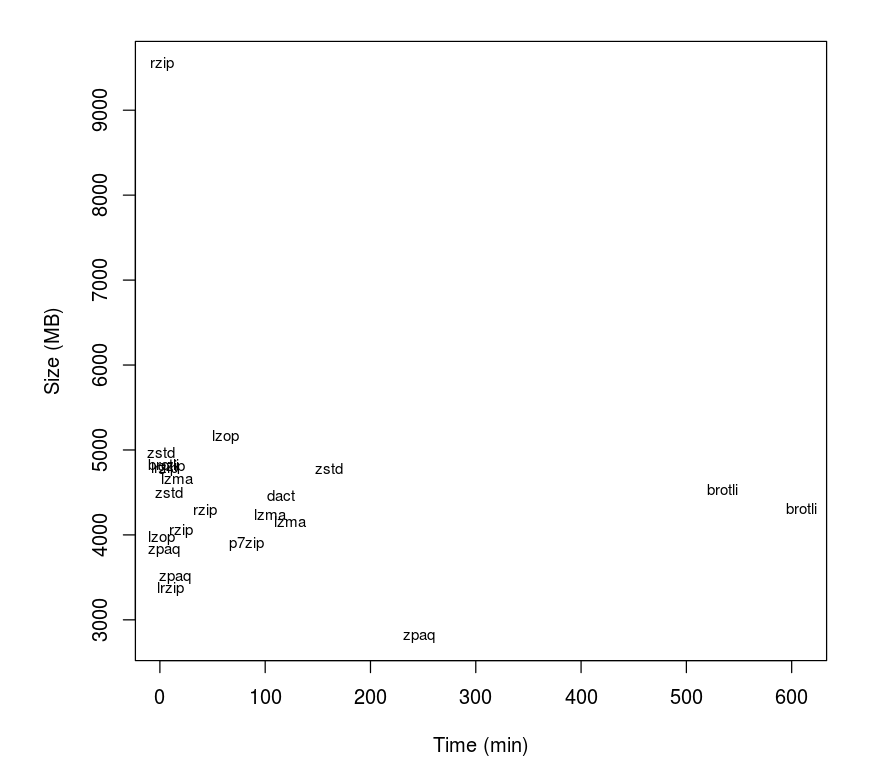
Here I’ve plotted the time it took to compress the file against the final output size. Right from the stop we can see that most of programs cluster together with a couple that lie well outside at the periphery. From this plot we can see that there are clear “winners” in terms of compressing the file to a smaller size while taking less time, such as p7zip verses lzma or dact. To make the comparison a bit clearer, let’s take the natural logarithm of both sides to pull the cluster apart.

Here we can see that the various programs vary much more in terms of computational time rather than final output size (21.8–23 vs 4–11). A couple things stand out such as the rzip sitting well above the rest in terms of size and the zpaq laying below. Overall, there are a lot of programs which all generate the same sized file (approximately) while ranging in time considerably.