This post is an elaboration of an iRKernel Notebook which can be found at http://misc.tkelly.org/Which_Witch.html. For a previous article on the iPython Notebook, see here.
Every programming language comes pre-packaged with certain basic functions, or methods, that are considered standard. These generally include methods for sorting objects, conversions between basic types (e.g. integer $\leftrightarrow$ float $\leftrightarrow$ string), et cetera and are referred to as the Standard Library. While functions in the standard library of any widely-used language are guaranteed to be reliable and robust, it wouldn’t be too hard to imagine one of two things:
- A. Optimization is not always a priority when reliability is a must.
- B. If you make something general-purpose then it’s easy to sacrifice the bit of performance that comes with specificity and assumptions.
While (A) is more a gut feeling, (B) is almost always going to be true since any function that takes a wide variety of input (or has to deal with potential variability) has to branch and run checks. The same function without those checks or error-catching should, in theory, always be faster. As we all know, theory doesn’t necessarily work in the real world.
My goal here was to take the source code for a simply {base} function in R and try to make it faster. First let’s take a look at a section of the source in the aptly named which.r. The which() function takes statement involving an array (or matrix[1]) and returns the indices of the elements that qualify. So this is a long winded way of saying:
x = c(1:6)^2 y = which(x%%2 == 0) print(x) print(y) > 1 4 9 16 25 36 > 2 4 6
On to the which.r file.
# File src/library/base/R/which.R
# Part of the R package, http://www.R-project.org
#
# Copyright (C) 1995-2013 The R Core Team
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# A copy of the GNU General Public License is available at
# http://www.r-project.org/Licenses/
which <- function(x, arr.ind = FALSE, useNames = TRUE)
{
wh <- .Internal(which(x))
if (arr.ind && !is.null(d <- dim(x)))
arrayInd(wh, d, dimnames(x), useNames=useNames) else wh
}
Ignoring all the comments, there is not a whole lot to the function. After it defines $wh$ as a .Internal, it branches depending on if you want named indices or just the index itself. Since I’m not sure where to find source for .Internal functions, my hands are bound for the time being.
For the first attempt, I decided to write the function from scratch using basic R commands that I know. Without being able to see the code for the internal which() function, this test would at least show me if I can even get close on my own.
which2 = function(x) {
c(1:length(x))[x<0]
}
Nothing magical here, the function simply makes a logical vector and then returns the indices of the true ones. The other way to speed up the function is to make a streamlined version of the built in one.
which3 <- function(x)
{
.Internal(which(x))
}
Notice the if statement in the original, that is called a ‘branch’ and it is a sure-fire way to slow down the execution of a function. Every time there’s a branch, the processor has to wait until all the cards are dealt before moving on. Take for example a statement like:
if( dice roll = 2) then …
In this case the computer has to wait for the dice roll before continuing[2]. If this is removed then the processor can simply move forward.
So how do these three different functions compare? Using microbenchmark I tested the execution time for all three functions.
silent("microbenchmark")
x = c(1:100)
y = sin(x)+0.5
results = microbenchmark(which(y<0), which2(y), which3(y<0))
plot(results, main="Comparison of which() functions", ylab="Time", xlab="Function", ylim=c(0,6000))
avg = summary(results)$median
text(x=1,y=0, paste0(format({avg[1]/avg[1]},digits=2), "x"))
text(x=2,y=0, paste0(format({avg[2]/avg[1]},digits=2), "x"))
text(x=3,y=0, paste0(format({avg[3]/avg[1]},digits=2), "x"))
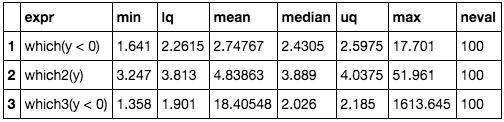
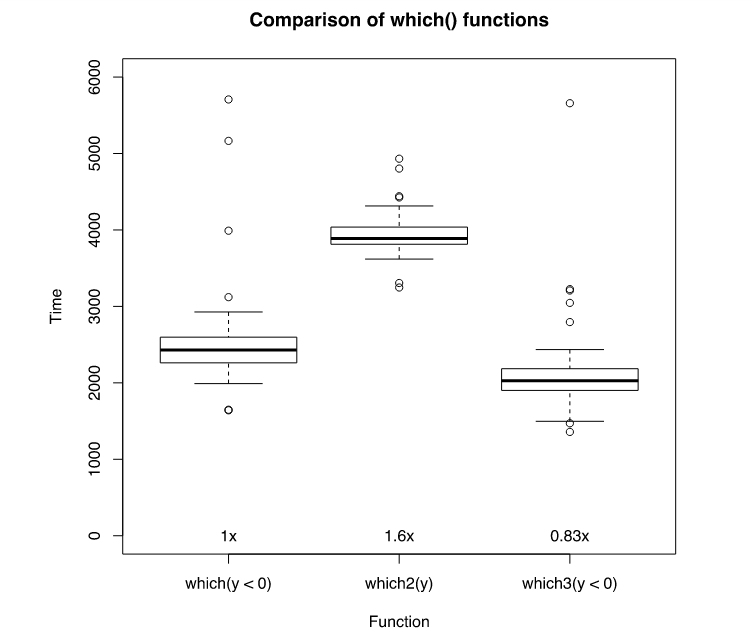
Not surprisingly, the streamlined function is quicker by a small, yet significant, amount. Also not surprisingly, the function I wrote is not nearly as fast. Without seeing the voodoo of the .Internal function I can’t even speculate as to the reason, but I would bet that the function is written in C rather than R.
Hope this was helpful and perhaps even inspiration for your own investigation.
Notes
- I’m not interested in using it for matrices.
- This is also a good example a different and more complex notion called predictive branching, but I’ll leave that for another time.
Found your article on R-bloggers.
“Without seeing the voodoo of the .Internal function I can’t even speculate as to the reason,”
Whenever I am interested in R compiled (FORTRAN or C or C++) source code, I head to https://github.com/wch/r-source
And more specifically to names.c https://github.com/wch/r-source/blob/trunk/src/main/names.c#L250 as explained here: http://stackoverflow.com/a/14035586/6197649
This tells me to look for do_which.
Then I do a global search in the repository https://github.com/wch/r-source/search?q=do_which&utf8=%E2%9C%93 and I find https://github.com/wch/r-source/blob/e4c924096a3327b519e4874f6e18713b285a13a2/src/main/summary.c#L907
So the voodoo appears to be:
/* which(x) : indices of non-NA TRUE values in x */
SEXP attribute_hidden do_which(SEXP call, SEXP op, SEXP args, SEXP rho)
{
SEXP v, v_nms, ans, ans_nms = R_NilValue;
int i, j = 0, len, *buf;
checkArity(op, args);
v = CAR(args);
if (!isLogical(v))
error(_(“argument to ‘which’ is not logical”));
len = length(v);
buf = (int *) R_alloc(len, sizeof(int));
for (i = 0; i < len; i++) {
if (LOGICAL(v)[i] == TRUE) {
buf[j] = i + 1;
j++;
}
}
len = j;
PROTECT(ans = allocVector(INTSXP, len));
if(len) memcpy(INTEGER(ans), buf, sizeof(int) * len);
if ((v_nms = getAttrib(v, R_NamesSymbol)) != R_NilValue) {
PROTECT(ans_nms = allocVector(STRSXP, len));
for (i = 0; i < len; i++) {
SET_STRING_ELT(ans_nms, i,
STRING_ELT(v_nms, INTEGER(ans)[i] – 1));
}
setAttrib(ans, R_NamesSymbol, ans_nms);
UNPROTECT(1);
}
UNPROTECT(1);
return ans;
}
Aurèle, that is a great example of tracking down a question through the source code and definitely inspires me to brush up on my C. Without really going into the performance constraints on the code used here it would be hard to try and push the current implementation any further. Thanks for your help in uncovering a part of the “magic black box”!